Splunk SmartStore S3 配置笔记
Splunk SmartStore S3 配置笔记
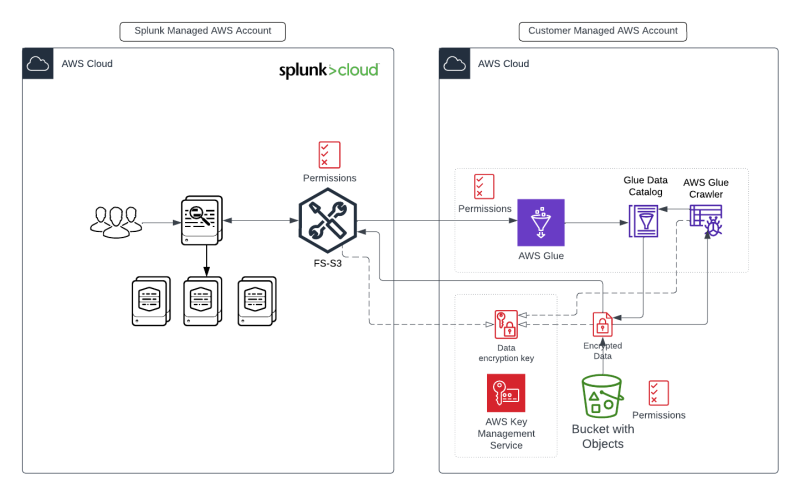
SmartStore系统要求
启用SmartStore的索引器的要求与未启用SmartStore的索引器基本相同。主要区别是:
- 需要有本地存储
- 需要链接的远程存储
索引器节点要求
索引器托管选项
用于SmartStore的对象存储类型决定了索引器必须托管的位置:
- 使用AWS S3远程存储运行SmartStore的索引器必须托管在AWS上。
- 使用GCP GCS远程存储运行SmartStore的索引器必须托管在GCP上。
- 使用Azure Blob远程存储运行SmartStore的索引器必须托管在Azure上。
- 运行具有符合S3 API的本地对象存储的SmartStore的索引器必须托管在本地数据中心中。
本地存储要求
根据您的索引器部署类型,按以下方式调配本地存储:
- 如果是在本地Linux计算机上运行Splunk Enterprise索引器,则首选本地存储类型为SSD。
- 如果是在AWS上运行Splunk Enterprise索引器,请将AWS与NVMe SSD实例存储(例如AWS i3 ens或i3 s)配合使用。
- 如果是在GCP上运行Splunk Enterprise索引器,请使用N1-高内存机器类型(n1-highmix-64或n1-highmix-32首选)和分区SSD持久磁盘。
- 如果是在Azure上运行Splunk Enterprise索引器,请使用具有高内存实例+ SSD(E系列,如Edv 4和Edsv 4系列)的Azure。
内部部署的操作系统要求
如果您在数据中心运行Splunk Enterprise,则每台本地计算机都必须运行相同的Linux 64位操作系统。
SmartStore的内部部署不支持其他操作系统。<我理解SmartStore只支持Linux 64操作系统>
Splunk Enterprise版本要求
独立索引器必须运行Splunk Enterprise 7.2或更高版本。
网络要求
索引器是远程存储的客户端,使用标准https端口与之通信。
为了获得最佳性能,请使用从每个索引器到远程存储的10 Gbps网络连接。
远程存储要求
SmartStore可以在AWS S3远程存储(包括符合S3 API的本地对象存储)、GCP GCS远程存储或Azure Blob远程存储上运行。根据计划部署的远程存储类型,请参阅为SmartStore配置S3远程存储、为SmartStore配置GCS远程存储或为SmartStore配置Azure Blob远程存储
❗Multiple indexer clusters or standalone indexers cannot access the same remote volume. In other words, the value of any
path setting inindexes.conf must be unique to a single running indexer or cluster. Do not sharepath settings among multiple indexers or clusters.多个索引器群集或独立索引器无法访问同一个远程卷。换句话说,
indexs.conf中的任何路径设置的值对于单个正在运行的索引器或集群都必须是唯一的。不要在多个索引器或群集之间共享路径设置。
⭐理解:IDX集群与IDX集群不能同时访问同一个远程存储volume,单节点IDX与单节点IDX不能同时访问同一个远程存储volume。单节点IDX与集群不能访问同一个远程存储volume。同一个Indexes cluster中的peer nodes可以同时访问同一个远程存储volume。
参考链接:https://docs.splunk.com/Documentation/Splunk/9.3.2/Indexer/ChooseSmartStorestoragelocation
配置S3远程存储
支持的S3远程存储
支持的远程存储服务包括S3<AWS S3和S3 符合S3存储API的对象存储>、Google GCS和Microsoft Azure Blob存储。有关GCS的信息,请参阅为SmartStore配置GCS远程存储。有关Azure Blob存储的信息,请参阅为SmartStore配置Azure Blob远程存储
S3检查
Splunk 官方提供的S3兼容性检查工具:s3-tests
配置S3远程存储
- 存储桶必须具有读、写和删除权限
- 如果索引器在EC2上运行,请为使用它的EC2实例提供相同区域的存储桶
- S3存储桶只能由SmartStore使用。不要与其他工具共享S3存储桶,例如摄取操作和边缘处理器。
远程存储版本控制支持
远程存储版本控制支持是可选的,默认情况下为SmartStore打开。某些第三方远程存储不支持版本控制,因此必须关闭SmartStore功能。请与您的第三方供应商联系,并在必要时关闭版本控制。
若要关闭版本控制支持,请使用
indexs.conf中的remote.s3.supports_versioning设置。
remote.s3.supports_versioning默认设置为true,需要关闭版本控制支持将remote.s3.supports_versioning设置为false
Splunk Enterprise本地S3远程存储寻址
Splunk Enterprise自动为Amazon S3存储桶提供V1和V2模型。您可以使用任一模型,但Splunk Enterprise在与S3通信时会将V1 URI转换为V2。
使用V1模型,您可以像这样指定URI:
1 | |
使用V2模型,您可以像这样指定URI:
1 | |
类似地,如果您指定以amazonaws.com结尾的端点,Splunk Enterprise将从端点确定URI版本,因为结构是固定的。举例来说:
1 | |
或者
1 | |
配置例子:
1 | |
选择每个索引的存储位置
索引配置SmartStore,则可以在同一索引器或索引器群集上混合使用SmartStore索引和非SmartStore索引。您还可以为不同的SmartStore索引指定不同的远程卷。
在indexs.conf中定义的远程卷指向SmartStore存储温存储桶的远程存储,例如S3存储桶、GCS存储桶或Azure Blob存储容器上的位置。
总而言之,您可以从以下存储选项中进行选择:
所有索引都远程存储在单个卷上。
所有索引都远程存储在多个卷上。
有些索引存储在本地,有些则远程存储在一个或多个远程卷上。
即使有 SmartStore 索引,一些索引数据也会暂时存储在本地缓存中。然而,除了热点桶外,索引的桶的主副本存储在远程。为了简化,存储选项列表在讨论存储卷时假设索引的主副本,不考虑 SmartStore 缓存中存储的本地数据。
请记住这些限制:
- 每个远程卷限制为单个索引器集群或独立索引器。也就是说,每个远程存储只包含单个集群或独立索引器的桶。从配置角度来看,在
indexes.conf 中的每个远程卷段落中的path 设置必须对集群或索引器是唯一的。例如,如果一个集群上的索引使用特定的远程卷,那么任何其他集群或独立索引器上的索引都不能使用相同的远程卷。 - 每个 SmartStore 索引限制在一个远程卷上。该索引的所有热桶必须位于同一个远程存储中。
- 每个索引器或索引器集群在所有索引中仅限于使用单一远程存储类型。可用的远程存储类型包括 S3、GCS 或 Azure Blob 存储。
- 所有索引器集群上的对等节点必须使用相同的 SmartStore 设置。
使用远程存储服务进行身份验证
如何对远程存储服务进行身份验证取决于索引器或索引器集群使用的云基础设施。
如果索引器或索引器群集在Amazon Elastic Compute Cloud(EC2)上运行,您可以使用其身份和访问管理(IAM)角色中的访问密钥和密钥进行身份验证。
如果索引器或索引器集群不在EC2上运行,请使用indexs.conf中的硬编码键。以下是S3硬编码密钥的相关设置:
1
2
3remote.s3.access_key:在对远程存储系统进行身份验证时使用的访问密钥。
remote.s3.secret_key:在与远程存储系统进行身份验证时使用的密钥。
remote.s3.endpoint:远程存储系统的URL。此设置告诉索引器S3身份验证的位置。使用S3存储桶区域的值。例如,https://s3.us-west-2.amazonaws.com.
您使用的凭据(无论是来自IAM角色还是来自indexs.conf)都需要执行S3操作的权限。如果您要加密远程存储上的静态数据,它们还需要执行Amazon Key Management Service(KMS)操作的权限。
实战案例:本地S3存储配置
使用本地Ceph S3存储保存Splunk数据
本地Ceph S3存储配置参数
1 | |
Splunk indexs.conf配置
1 | |
参考链接
https://docs.splunk.com/Documentation/Splunk/9.3.2/Indexer/ChooseSmartStorestoragelocation