读取pdf文件内容获取单词通过有道API进行翻译
Python代码
import sys
import uuid
import requests
import hashlib
import json
import time
import pdfplumber
import jieba
from collections import Counter
from string import digits
from imp import reload
import xlwt
def encrypt(signStr):
hash_algorithm = hashlib.sha256()
hash_algorithm.update(signStr.encode('utf-8'))
return hash_algorithm.hexdigest()
def truncate(q):
if q is None:
return None
size = len(q)
return q if size <= 20 else q[0:10] + str(size) + q[size - 10:size]
def PdfIdentifyText():
PdfContent = ""
with pdfplumber.open('./file/SPLK-1001.199Q.pdf') as pdf: # 利用pdfplumber提取文字
for temp in pdf.pages:
PdfContent += temp.extract_text()
tokens = jieba.cut(PdfContent) # 使用jieba将全文分割,并将大于两个字的词语放入列表
return Counter(tokens).most_common()
def tranRequest(query_word):
reload(sys)
YOUDAO_URL = 'https://openapi.youdao.com/api'
APP_KEY = 'xxxx'
APP_SECRET = 'xxxx'
data = {}
q = query_word
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
data['from'] = 'en'
data['to'] = 'zh-CHS'
data['signType'] = 'v3'
curtime = str(int(time.time()))
data['curtime'] = curtime
salt = str(uuid.uuid1())
signStr = APP_KEY + truncate(q) + salt + curtime + APP_SECRET
sign = encrypt(signStr)
data['appKey'] = APP_KEY
data['q'] = q
data['salt'] = salt
data['sign'] = sign
# data['vocabId'] = "您的用户词表ID"
retult = requests.post(YOUDAO_URL, data=data, headers=headers)
contentType = retult.headers['Content-Type']
if contentType == "audio/mp3":
millis = int(round(time.time() * 1000))
filePath = "./file/" + str(millis) + ".mp3"
fo = open(filePath, 'wb')
fo.write(retult.content)
fo.close()
else:
return json.loads(retult.text)
# 将结果保存到csv文件中
def ToCsvFile(data):
data = data["count"]+ "," + data["EnglishWord"] + "," + data["EnglishExplains"]+'\r\n'
csvFile.write(data.encode()) # 文件写入
def DataClea(data):
for temp in data:
if len(temp[0].translate(str.maketrans('', '', digits))) > 1:
tranRequestContent = tranRequest(temp[0]) # 创建请求获取单词注释
dictWord = {}
dictWord["count"] = str(temp[1])
dictWord["EnglishWord"] = tranRequestContent["query"].lower() # 查询英文单词
try:
dictWord["EnglishExplains"] = "||".join(tranRequestContent["basic"]["explains"]) # 中文注释
except:
print(tranRequestContent["query"].lower() + '单词翻译出错!')
dictWord["EnglishExplains"] = " "
ToCsvFile(dictWord)
if __name__ == '__main__':
csvFile = open('./file/works.csv', "wb") # 打开csv文件
PdfTextContent = PdfIdentifyText()
DataCleaContent = DataClea(PdfTextContent)
csvFile.close() # 关闭csv文件
效果截图

执行截图
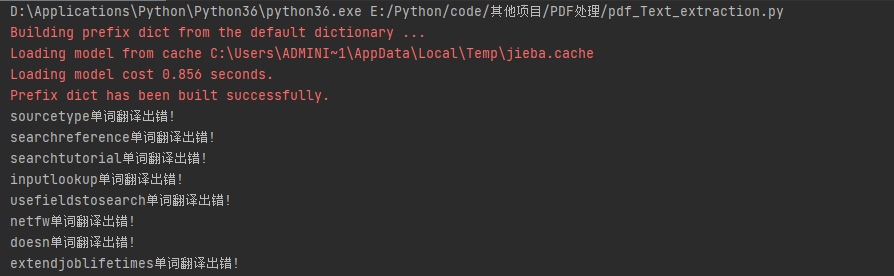


-d2979772834f4346a961b123d2a49447.jpg)


评论区