

一、简要概述
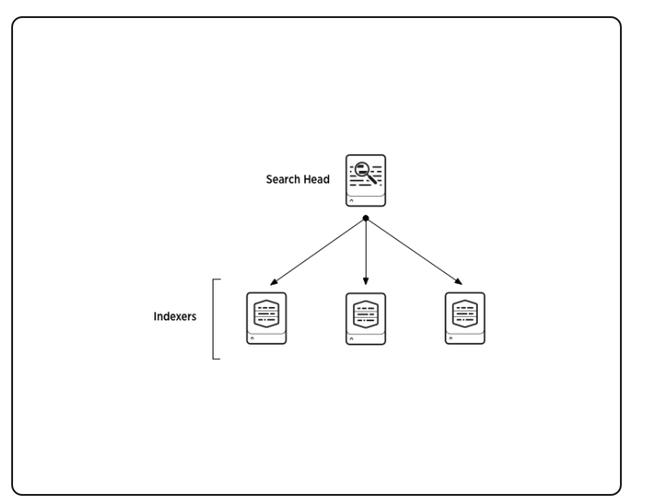
Search head会将search request发送给index节点,然后合并返回结果,基本的流程图如下所示:
二、request 包含哪些东西?
search head会发送成为knowledge object的东西给index节点,这个knowledge中包含了已保存的搜索语句,事件类型和其它的组件,目的是为了能让index节点正确执行语句。searchhead在初始化一个search任务的时候会周期性的后台同步这个数据给搜索节点。
同步过程支持全量和增量,首次同步时为全量,后续的为增量,文件位置在$SPLUNK_HOME/var/run目录下,全量的为.bundle,增量的为.delta压缩包,在同步期间,index节点会将收到的knowledge bundles存放在$SPLUNK_HOME/var/run/searchpeers目录下。
同步复制方式有四种:
classic:由search head统一下发
cascading:searchhead下发几个节点,再由这些节点互传(主要用在多个search对等体上)
mounted:放在共享存储上
rfs:目前还不支持
三、分布式搜索过程
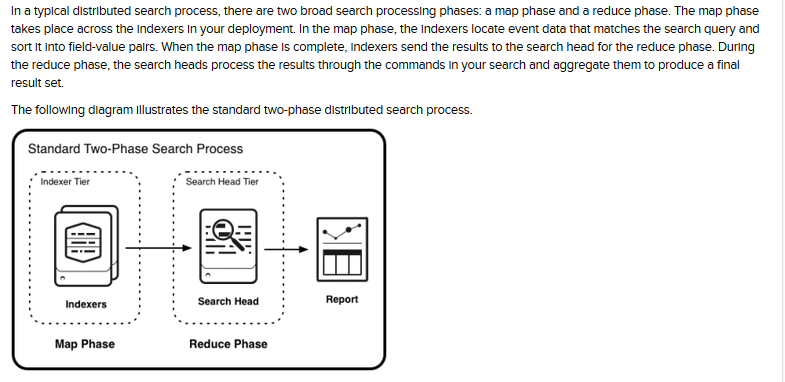
典型的map-reduce
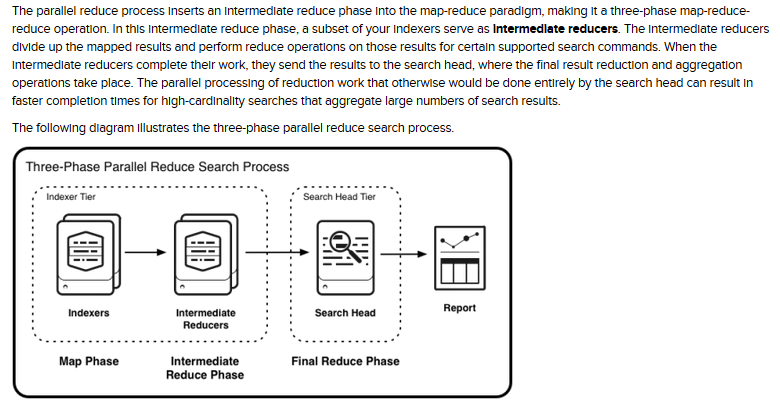
而splunk的map-reduce过程(版本7.1.0以后支持)
参考链接:
https://docs.splunk.com/Documentation/Splunk/8.0.0/DistSearch/SHCsystemrequirements
-d2979772834f4346a961b123d2a49447.jpg)


评论区